2D Convolution Tutorial¶
This tutorial shows how 2D convolution is implemented using Wave. The implementation lowers convolution into a tiled matrix multiplication using a strategy commonly referred to as indirect GEMM (iGEMM).
The kernel is generated by the function:
get_igemm_conv2d(...)
This function returns a Wave kernel that computes 2D convolution with a configurable layout and tiling scheme.
What is 2D Convolution?¶
A 2D convolution slides a filter over a 2D input image or feature map, applying dot products at each location. Each filter produces one output channel.
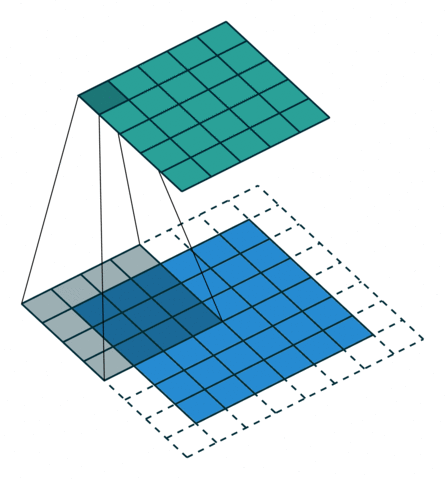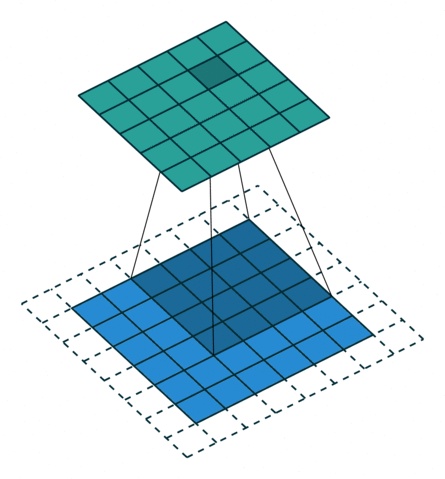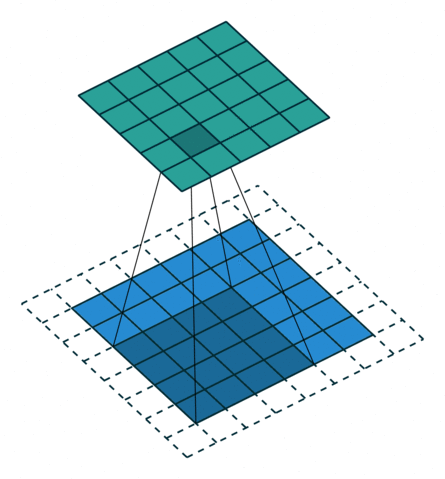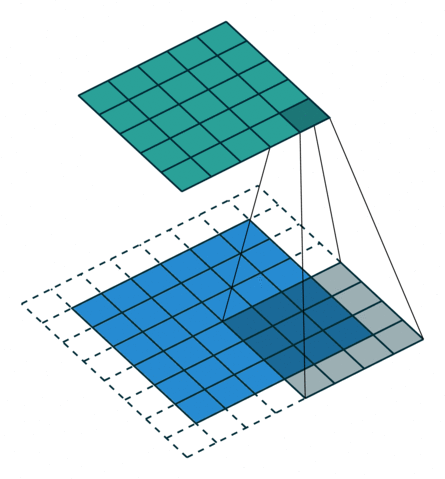
The above gif is an example of convolution where the blue matrix is the input matrix, the gray matrix is the filter which is sliding across the input matrix and the green matrix is the output matrix.
Variable Definitions¶
The following table defines the variables used in the convolution shapes:
Variables:
Variables:
N- Batch size (number of input images)H, W- Input image height and widthC- Number of input channels (e.g., 3 for RGB)HF, WF- Filter (kernel) height and widthNF- Number of filters (also the number of output channels)H_out, W_out- Output spatial height and width after convolution
For an input tensor of shape:
(N, H, W, C)
and a weight tensor of shape:
(HF, WF, C, NF)
the output has shape:
(N, H_out, W_out, NF)
where:
H_OUT = (H + 2 * padding - HF) // stride + 1
W_OUT = (W + 2 * padding - WF) // stride + 1
Currently Padding can only be set to 0 (no padding).
Lowering to iGEMM¶
To optimize the convolution for GPU execution, we flatten it into a matrix multiplication:
The input is reshaped to an
(M × K)matrix, where: -M = N × H_out × W_out(one row per output spatial location) -K = HF × WF × C(flattened filter field)The filter weights are reshaped to
(K × NF)The result is an
(M × NF)output matrix
This is then reshaped back to (N, H_out, W_out, NF).
M and K are calculated in the Kernel here using Symbolics:
SZ_OUT = H_OUT * W_OUT
K = HF * WF * C
M = SZ_OUT * N
Wave DSL Implementation¶
The function defines a kernel with the following key components:
1. Index Mappings
Three index mappings define how loop indices correspond to tensor memory accesses:
x_mapping = tkw.IndexMapping(...)
w_mapping = tkw.IndexMapping(...)
out_mapping = tkw.IndexMapping(...)
2. Loop Nest and MMA
The kernel loops over the dimension K, loading tiles from input and weight tensors, and accumulating partial results using tkw.mma(…). Final results are written using tkw.write(…).
@tkw.wave(constraints)
def conv(x, we, out):
c_reg = tkl.Register[M, NF, output_dtype](0.0)
@tkw.iterate(K, init_args=[c_reg])
def repeat(acc):
a_reg = tkw.read(x, mapping=x_mapping, ...)
b_reg = tkw.read(we, mapping=w_mapping, ...)
acc = tkw.mma(a_reg, b_reg, acc)
return acc
tkw.write(repeat, out, mapping=out_mapping, ...)
Tiling and Scheduling¶
To optimize performance, the kernel exposes tiling parameters:
block_m, block_n, block_k: tiling factors for matrix dimensions
ratio_m, ratio_n: number of waves per block in M/N directions
ELEMS_PER_THREAD: how many elements each thread processes
These are passed as symbolic constraints and can be tuned per hardware target.
Symbol Table¶
The function returns both the kernel and a symbol dictionary:
conv_kernel, symbols = get_igemm_conv2d(...)
# symbols = { N: 1, C: 3, H: 32, ... }
These values are used during compilation to resolve symbolic shapes.
Summary¶
The get_igemm_conv2d function offers a flexible and tunable approach to implement 2D convolution using the Wave DSL. It transforms the convolution into a matrix multiply, applies GPU-friendly tiling, and uses register and wave-level operations for efficiency.